|
My primary areas of research are 3D computer vision including 3D reconstruction and neural rendering. I'm always open to collaborations or suggestions. Please feel free to contact me if you have any questions or suggestions. :) Email / CV / Google Scholar / Github / Linkedin |

|
|
[Feb. 2026] Two papers got accepted at CVPR 2026 including one Findings! |
|
My first-author papers are highlighted with a yellow background. |
|
|
Wonjoon Lee, Sungmin Woo, Donghyeong Kim, Jungho Lee, Sangheon Park, Sangyoun Lee IEEE/CVF Computer Vision and Pattern Recognition (CVPR), 2026 project page / arXiv / code We propose MoRGS, an efficient online per-Gaussian motion reasoning framework that explicitly models per-Gaussian motion to improve 4D reconstruction quality. |
|
|
Jungho Lee, Minhyeok Lee, Sunghun Yang, Minseok Kang, Sangyoun Lee IEEE/CVF Computer Vision and Pattern Recognition (CVPR) Findings, 2026 project page / arXiv / code We propose SwiftVGGT, a training-free method that significantly reduce inference time while preserving high-quality dense 3D reconstruction. |
|
|
Sunghun Yang, Minhyeok Lee, Jungho Lee, Sangyoun Lee The Association for the Advancement of Artificial Intelligence (AAAI), 2026 arXiv / code We propose MonoCLUE, which enhances monocular 3D detection by leveraging both local clustering and generalized scene memory of visual features. |

|
Jungho Lee, Donghyeong Kim, Dogyoon Lee, Suhwan Cho, Minhyeok Lee, Wonjoon Lee, Taeoh Kim, Dongyoon Wee, Sangyoun Lee IEEE/CVF International Conference on Computer Vision (ICCV), 2025 project page / arXiv / code We propose continous motion-aware blur kernel on 3D gaussian splatting utilizing 3D rigid transformation and neural ordinary differential function to reconstruct accurate 3D scene from blurry images with real-time rendering speed. |
|
|
Dogyoon Lee, Donghyeong Kim, Jungho Lee, Minhyeok Lee, Seunghoon Lee, Sangyoun Lee IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) project page / arXiv Sparse-DeRF effectively addresses the challenging optimization problem posed by sparse blurry imagers, while simultaneously modeling clean radiance fields. More over, it proposes a more practical research direction by considering real-world scenarios. |

|
Jungho Lee, Suhwan Cho, Taeoh Kim, Ho-Deok Jang, Minhyeok Lee, Geonho Cha, Dongyoon Wee, Dogyoon Lee, Sangyoun Lee IEEE/CVF Computer Vision and Pattern Recognition (CVPR), 2025 project page / arXiv / code CoCoGaussian models the CoC at the 3D Gaussian level, reconstructing the precise 3D scene and enabling sharp novel view synthesis from defocused images. |


|
Minhyeok Lee, Suhwan Cho, Jungho Lee, Sunghun Yang, Heeseung Choi, Ig-Jae Kim, Sangyoun Lee IEEE/CVF Computer Vision and Pattern Recognition (CVPR), 2025 arXiv / code We propose a novel one-stage open-vocabulary semantic segmentation model, which effectively combines CLIP and SAM to leverage SAM’s powerful classagnostic segmentation capabilities while maintaining efficient inference. |

|
Jungho Lee, Dogyoon Lee, Minhyeok Lee, Donghyeong Kim, Sangyoun Lee IEEE/CVF Computer Vision and Pattern Recognition Workshop (CVPRW), 2025 project page / arXiv / code We propose novel blur kernel for motion estimation based on neural ordinary differential function to construct the deblurred neural radiance fields. |
|
|
Minhyeok Lee, Suhwan Cho, Chajin Shin, Jungho Lee, Sunghun Yang, Sangyoun Lee The Association for the Advancement of Artificial Intelligence (AAAI), 2025 arXiv / code We design a First Frame Filling Video Diffusion Inpainting model inspired by the capabilities of pre-trained image-to-video diffusion models that can transform the first frame image into a highly natural video. |
|
|
Minhyeok Lee, Suhwan Cho, Dogyoon Lee, Chaewon Park, Jungho Lee, Sangyoun Lee IEEE/CVF Computer Vision and Pattern Recognition (CVPR), 2024 arXiv / code We propose a guided slot attention network to reinforce spatial structural information and obtain better foreground–background separation. |

|
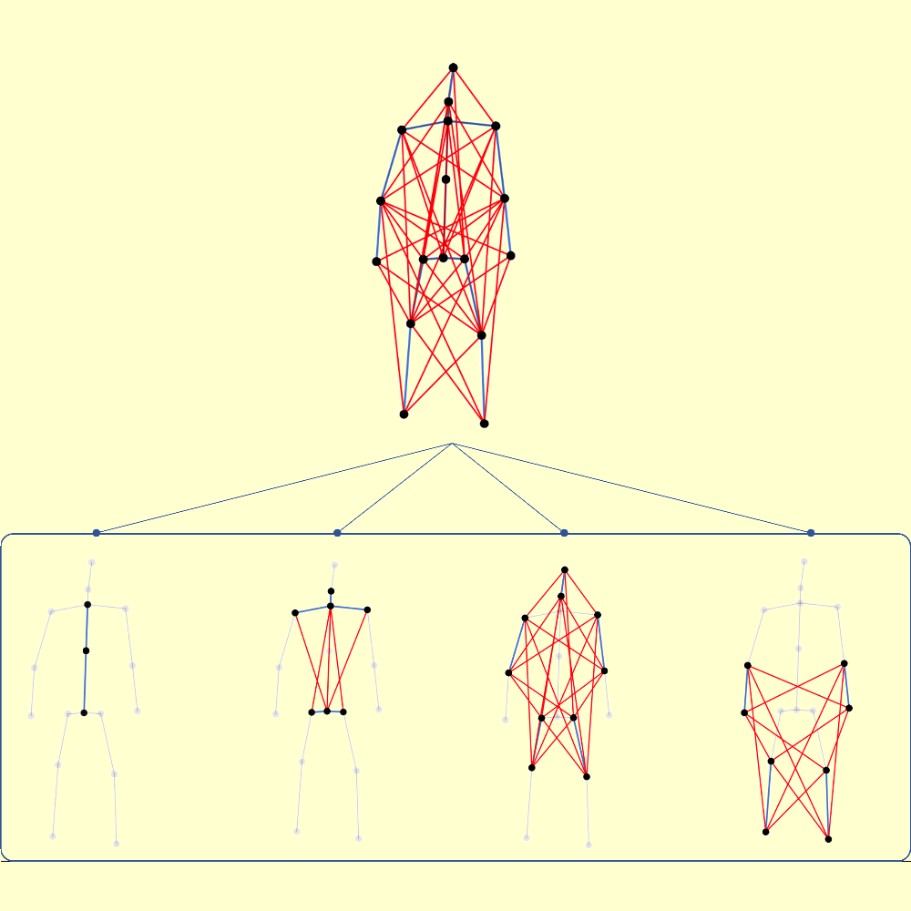
Jungho Lee, Minhyeok Lee, Dogyoon Lee, Sangyoun Lee IEEE/CVF International Conference on Computer Vision (ICCV), 2023 arXiv / code We propose a hierarchically decomposed graph convolution with a novel hierarchically decomposed graph, which consider the sematic correlation between the joints and the edges of the human skeleton. |

|
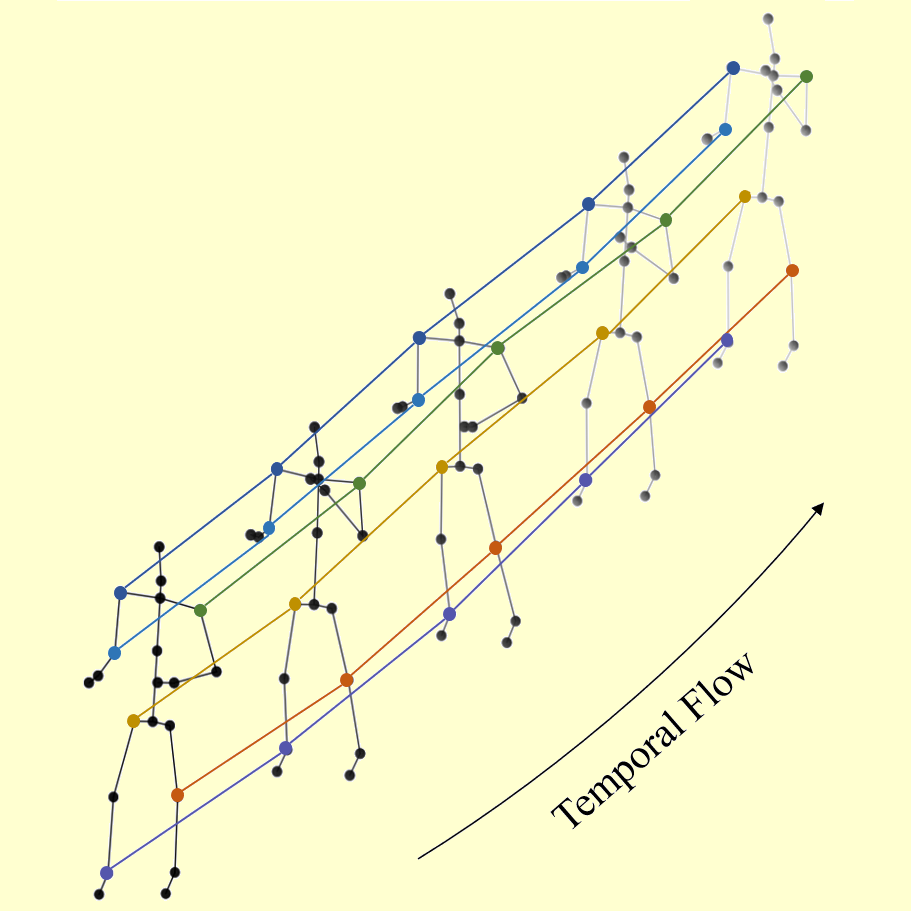
Jungho Lee, Minhyeok Lee, Suhwan Cho, Sungmin Woo, Sungjun Jang, Sangyoun Lee IEEE/CVF International Conference on Computer Vision (ICCV), 2023 arXiv / code We propose a novel Spatio-Temporal Curve Network (STC-Net) for skeleton-based action recognition, which consists of spatial modules with an spatio-temporal curve (STC) module and graph convolution with dilated kernels (DK-GC) |
|
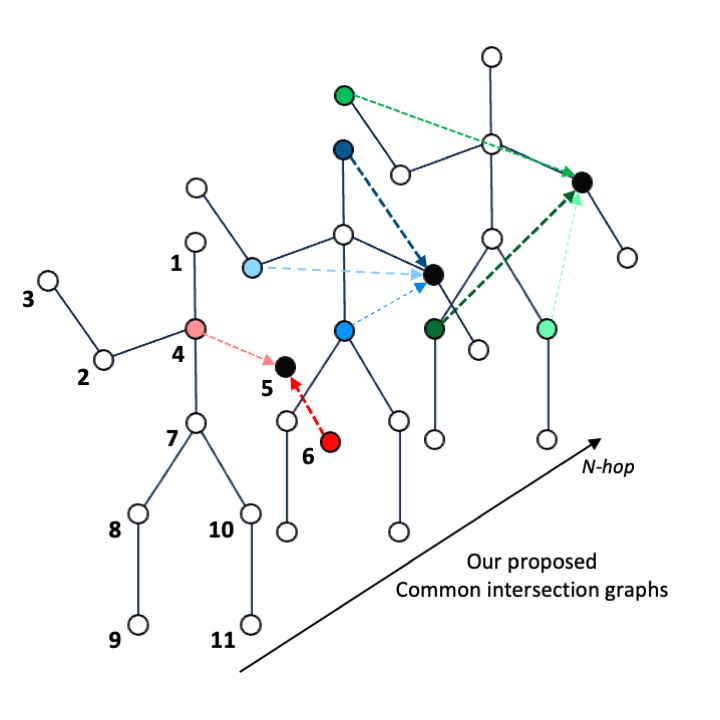
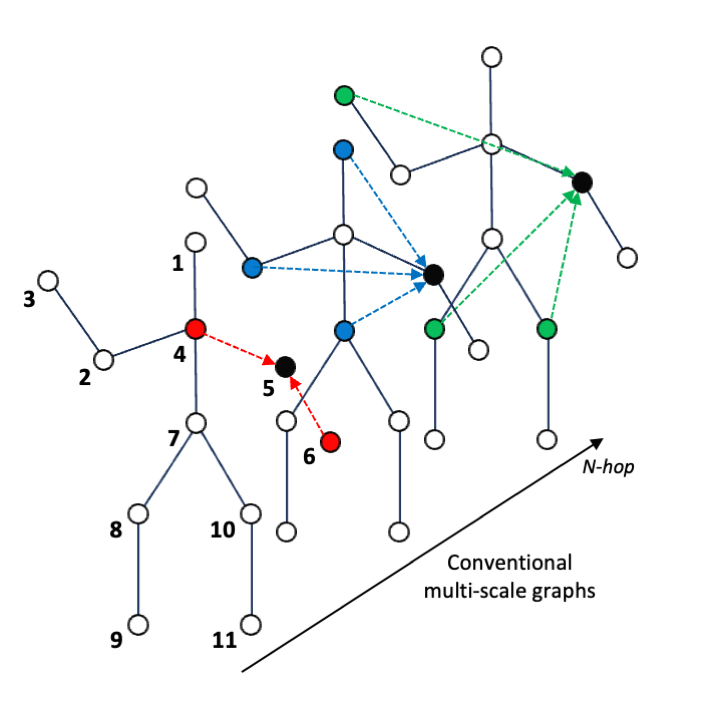
Sungjun Jang, Heansung Lee, Woo Jin Kim, Jungho Lee, Sungmin Woo, Sangyoun Lee IEEE Transactions on Circuits and Systems for Video Technology (TCSVT) paper We propose the multi-scale structural graph convolutional network, the common intersection graph convolution leverages the overlapped neighbor information between neighboring vertices for a given pair of root vertices. |
|
This website's source code is borrowed from Jon Barron's website template. Last updated December 2024. |